Meta ha annunciato Llama 4, una nuova famiglia di modelli di intelligenza artificiale progettati per elaborare simultaneamente testo, immagini, video e audio. Questi modelli rappresentano un significativo avanzamento rispetto ai loro predecessori, offrendo miglioramenti in termini di prestazioni, efficienza e neutralità nelle risposte a domande sensibili.
Caratteristiche principali di Llama 4
La serie Llama 4 include due modelli principali:
- Llama 4 Scout: un modello compatto ottimizzato per funzionare su una singola GPU Nvidia H100. Offre una finestra di contesto di 10 milioni di token e supera concorrenti come Gemma 3 di Google e Mistral 3.1 in vari benchmark.
- Llama 4 Maverick: un modello più grande con prestazioni comparabili a GPT-4o di OpenAI e DeepSeek-V3 in attività di codifica e ragionamento, utilizzando meno della metà dei parametri attivi.
Meta sta inoltre sviluppando Llama 4 Behemoth, un modello con 288 miliardi di parametri attivi e un totale di 2 trilioni, che si prevede supererà modelli come GPT-4.5 e Claude Sonnet 3.7 nei benchmark STEM.
Pre-training
I modelli Llama 4 introducono per la prima volta l’architettura Mixture of Experts (MoE). In un modello MoE, ogni token attiva solo una parte dei parametri, rendendo l’addestramento e l’inferenza più efficienti. A parità di FLOPs, i MoE offrono qualità superiore rispetto ai modelli densi.
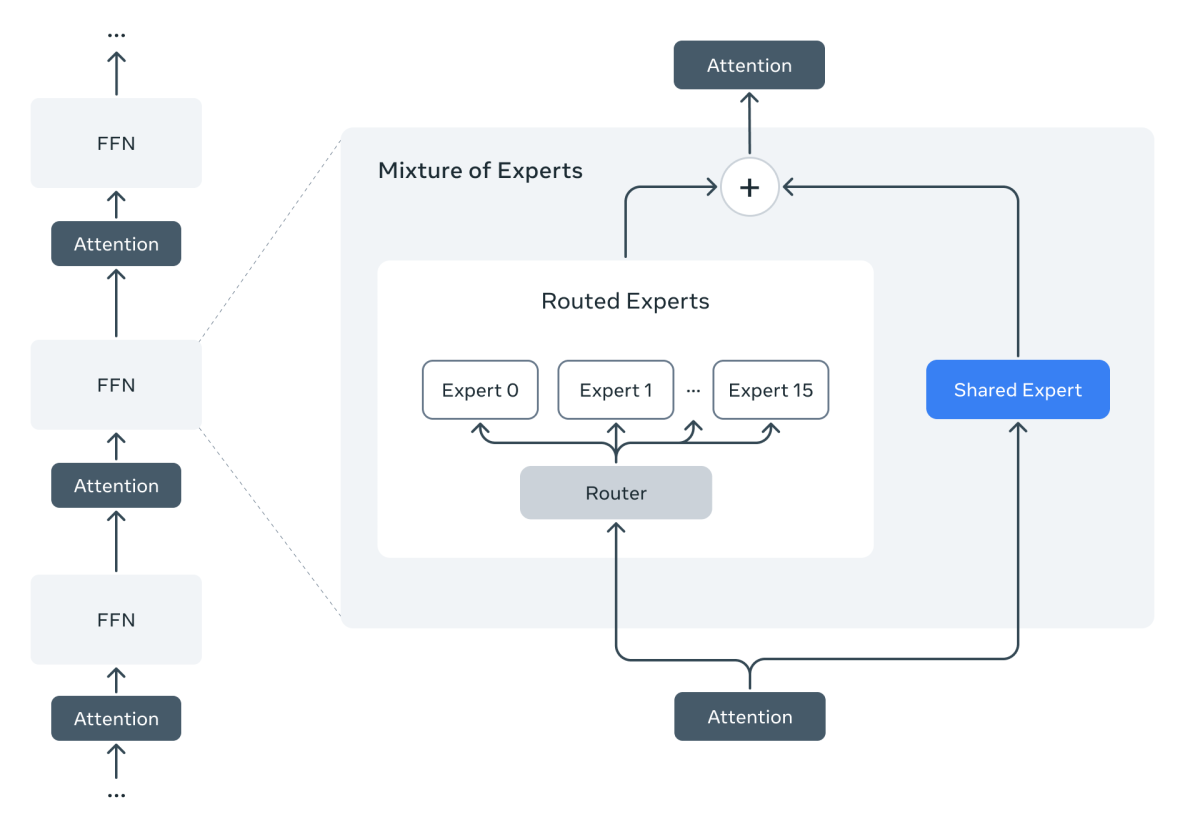
Llama 4 Maverick ha 17 miliardi di parametri attivi su un totale di 400 miliardi. Utilizza strati alternati densi e MoE. Ogni livello MoE ha 128 esperti “instradabili” e un esperto condiviso. Ogni token viene inviato sia all’esperto condiviso che a uno dei 128 esperti. Anche se tutti i parametri sono in memoria, solo una parte viene usata a ogni passo, riducendo costi e latenza. Il modello può essere eseguito su una singola macchina NVIDIA H100 DGX o distribuito su più nodi.
Llama 4 è progettato per la multimodalità nativa. Usa early fusion, cioè integra in modo diretto token testuali e visivi nello stesso backbone. Questo permette il pre-addestramento con grandi quantità di testo, immagini e video non etichettati.
Il vision encoder, basato su MetaCLIP, è stato riaddestrato separatamente insieme a un LLM congelato per adattarsi meglio alla struttura del modello.
Abbiamo sviluppato una nuova tecnica, chiamata MetaP, per impostare in modo stabile gli iperparametri critici: learning rate per strato, scale di inizializzazione, ecc. Questi iperparametri si sono dimostrati efficaci anche variando batch size, larghezza, profondità e numero di token.
Il pre-training è stato fatto su 200 lingue, con oltre 100 lingue che superano 1 miliardo di token ciascuna. In totale, Llama 4 ha visto 10 volte più dati multilingue rispetto a Llama 3.
Il training ha usato FP8 per migliorare l'efficienza computazionale senza perdere qualità. Il modello Behemoth è stato pre-addestrato su 32.000 GPU, raggiungendo 390 TFLOPs per GPU. Il dataset ha superato i 30 trilioni di token, più del doppio rispetto a Llama 3, includendo testo, immagini e video.
Abbiamo introdotto una fase di mid-training per rafforzare capacità di base, con nuove tecniche e dataset specializzati. Questo ha permesso di estendere il contesto fino a 10 milioni di token per il modello Llama 4 Scout..
Post-training
La linea Llama 4 include modelli di varie dimensioni. Maverick è il modello principale per uso generale e chat, con ottime prestazioni su testo e immagini. È adatto a scrittura creativa, comprensione visiva, e applicazioni AI multimodali.
La difficoltà maggiore nel post-training è stata bilanciare modalità multiple, ragionamento e dialogo. Abbiamo usato una strategia di curriculum curata per non sacrificare le performance rispetto a modelli specializzati.
La pipeline di post-training è composta da tre fasi:
- Supervised fine-tuning leggero (SFT)
- Reinforcement learning online (RL)
- Direct Preference Optimization leggero (DPO)
Abbiamo osservato che SFT e DPO troppo rigidi riducono la capacità del modello di esplorare durante il RL, con un impatto negativo su compiti di ragionamento, coding e matematica. Per evitare questo, abbiamo filtrato i dati di addestramento rimuovendo oltre il 50% dei prompt "facili", usando altri modelli Llama come giudici. Il SFT è stato eseguito solo sul set più difficile.
Durante il RL multimodale abbiamo usato prompt selezionati con difficoltà crescente. Inoltre, il modello stesso è stato usato per filtrare continuamente i dati, conservando solo quelli di media o alta difficoltà. Questo ha migliorato l’efficienza e la qualità.
Infine, il DPO leggero ha risolto casi limite legati alla qualità delle risposte, mantenendo un buon equilibrio tra intelligenza e capacità conversazionale.
Il risultato è un modello generale con prestazioni avanzate nella comprensione di testi, immagini, dialogo e ragionamento.
Llama 4 Maverick, con 17B parametri attivi, 128 esperti e 400B totali, offre prestazioni superiori a un costo inferiore rispetto a Llama 3.3 70B. Supera modelli come GPT-4o e Gemini 2.0 in coding, ragionamento, multilingua, contesto esteso e immagini, e tiene testa a modelli molto più grandi come DeepSeek v3.1..
Confronto con altri modelli
Ecco un confronto tra Llama 4 e altri modelli di intelligenza artificialein termini di parametri attivi e requisiti hardware:
| Modello | Parametri Attivi | Requisiti GPU per Addestramento |
|---|---|---|
| Llama 4 Scout | Non specificato | Singola Nvidia H100 |
| Llama 4 Maverick | Non specificato | Non specificato |
| Llama 4 Behemoth | 288 miliardi | Oltre 100.000 Nvidia H100 |
| GPT-4o (OpenAI) | Non specificato | Non specificato |
| DeepSeek-V3 | Non specificato | Non specificato |
| Gemma 3 (Google) | Non specificato | Non specificato |
| Mistral 3.1 | Non specificato | Non specificato |
Questo confronto evidenzia l'impegno di Meta nell'investire in infrastrutture hardware avanzate per supportare modelli di intelligenza artificiale sempre più complessi.
Architettura e requisiti hardware
L'adozione dell'architettura MoE in Llama 4consente una maggiore efficienza computazionale, attivando solo le parti del modello necessarie per un determinato compito. Tuttavia, l'addestramento di modelli di questa scala comporta costi significativi sia in termini di hardware che di consumo energetico. Secondo stime, un cluster di 100.000 GPU Nvidia H100 potrebbe richiedere circa 150 megawatt di potenza peroperare.
Benchmark di Llama 4 Maverick con tuning per istruzioni
| Benchmark per Categoria | Llama 4 Maverick | Gemini 2.0 Flash | DeepSeek v3.1 | GPT-4o |
|---|---|---|---|---|
| Costo di Inferenza | ||||
| Costo per 1M token di input & output (rapporto 3:1) | 0.19−0.19-0.19−0.49¹ | $0.17 | $0.48 | $4.38 |
| Ragionamento su Immagini | ||||
| MMMU | 73.4 | 71.7 | — | 69.1 |
| MathVista | 73.7 | 73.1 | Nessun supporto multimodale | 63.8 |
| Comprensione di Immagini | ||||
| ChartQA | 90.0 | 88.3 | — | 85.7 |
| DocVQA (test) | 94.4 | — | — | 92.8 |
| Programmazione | ||||
| LiveCodeBench (01/2024-02/2025) | 43.4 | 34.5 | 45.8/49.2³ | 32.3³ |
| Ragionamento & Conoscenza | ||||
| MMLU Pro | 80.5 | 77.6 | 81.2 | — |
| GPQA Diamond | 69.8 | 60.1 | 68.4 | 53.6 |
| Multilingue | ||||
| MMLU Multilingue | 84.6 | — | — | 81.5 |
| Contesto Lungo | ||||
| MTOB (mezzo libro) eng → kgv/kgv → eng | 54.0/46.4 | 48.4/39.8⁴ | Finestra di contesto: 128K | Finestra di contesto: 128K |
| MTOB (libro intero) eng → kgv/kgv → eng | 50.8/46.7 | 45.5/39.6⁴ | Finestra di contesto: 128K | Finestra di contesto: 128K |
Note:
- Per i modelli Llama, i risultati sono valutati senza esempi preliminari (0-shot), con temperatura = 0 e senza voto a maggioranza. Per benchmark ad alta varianza (GPQA Diamond, LiveCodeBench), viene calcolata la media su più generazioni per ridurre l'incertezza.
- Per i modelli non-Llama, sono riportati i risultati più alti autodichiarati, se disponibili. Sono inclusi solo modelli con valutazioni riproducibili (via API o pesi open).
- L'intervallo di dati per DeepSeek v3.1 è sconosciuto (48.2), quindi forniamo un risultato interno (45.8). I risultati per GPT-4o provengono dalla classifica LiveCodeBench.
- Le valutazioni specializzate per contesti lunghi non sono tradizionalmente riportate per i modelli generativi, quindi condividiamo test interni per mostrare le prestazioni di Llama.
- $0.19/Mtok (rapporto 3:1) è una stima per Llama 4 Maverick con inferenza distribuita. Su un singolo host, il costo previsto è $0.30-$0.49/Mtok (3:1 blended).
Disponibilità e integrazione
Imodelli Llama 4 sono integrati nell'assistente AI di Meta su piattaforme come WhatsApp, Messenger, Instagram eil web. Ulteriori sviluppisaranno discussi alla prossima conferenza LlamaCon di Meta, prevista per il 29 aprile.
Link al modello via huggingface meta-llama
Glossario
- MoE (Mixture of Experts): Architettura di rete neurale che utilizza più modelli specializzati (esperti) per gestire diversi aspetti di un compito, migliorando l'efficienza e le prestazioni complessive.
- GPU (Graphics Processing Unit): Processore specializzato nell'elaborazione parallela, utilizzato principalmente per il rendering grafico ma fondamentale nell'addestramento di modelli di intelligenza artificiale.
- Parametri Attivi: Numero di parametri effettivamente utilizzati durante l'inferenza in un modello di intelligenza artificiale.
- Inferenza: Processo mediante il quale un modello di intelligenza artificiale elabora nuovi dati dopo l'addestramento per produrre risultati o previsioni.